Deformable Convolution
变形卷积,在视频处理中,形变较大的 ocr 中会有不错的效果,在视频超分中有使用到这类模块
上面两篇文章都是用了变形卷积来增强时序性。
原理以及方法:
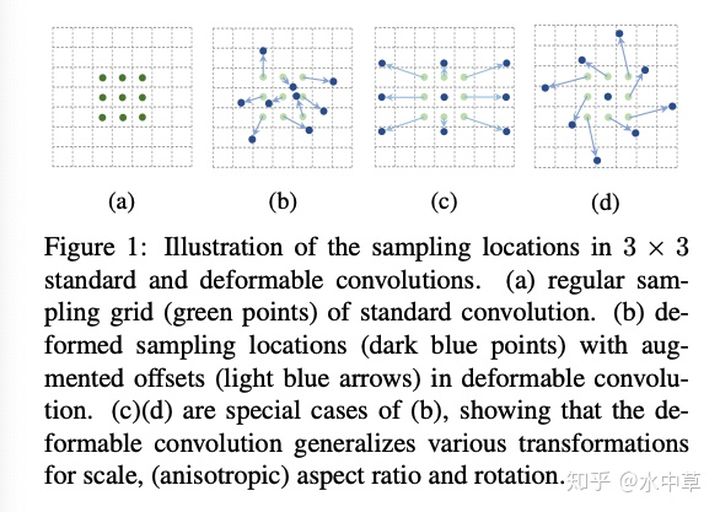
可以发现上面这个图中,预测的 offset 就是绿边,可以让原本参加 conv 的窗口进行变化。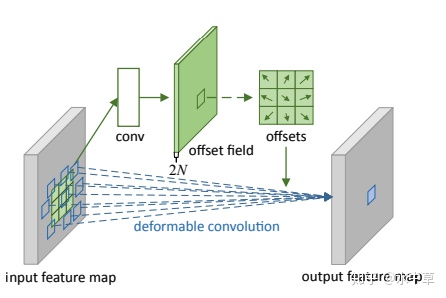
具体的做法是:基于 input 的 feature, 通过一个 offset 的预测卷积,这个 offset 是 [2N, H, W] 的 shape, 每一个点代表了该点卷积核位置的 offset, 具体来说就是如果卷积核大小为 3x3 那么就需要 N=9 个偏移值,在两个方向 (x, y) 都需要,总共需要 2N 个偏移。
另外,这里也涉及一个插值问题,因为 offset 并不是离散的而是连续的值,x(p0 + pn + ∆pn) (x 代表 feature map,p0 代表该核中心位置,pn 枚举核的任意位置,∆pn 则是偏移量) 很可能是亚像素,这时候需要插值去完成具体地,x(p=p0 + pn + ∆pn) = sum_q(G(q,p)*x(q)) , G(q,p) 定义为 G(q,p) = g(qx,px)*g(qy,py) g(a,b)=max(0, 1- |a-b|)
Deformable ROI Pooling
普通 RoI Pooling : 对于一张特征图 x 以及其 RoI, 首先将 RoI 分成 k * k 个 bins, 我们将每一个 bin 中的像素值进行取均值或者取最大值进行池化。
对于 num_deformable_group 的理解:
标准的变形卷积group_num = 1 对每一个 channel 都使用一样的 offset 这会造成单一性,类似于 group conv,可以针对不同的 channel 来实施不同的 offset。
Code 理解:
以EDVR中的 PCDAlignment 模块为例分析一下抛开多尺度金字塔结构,聚焦其中一层。t 帧,以及参考帧 t+i 帧 合并,通过两帧预测 offset,使用 dcn_pack 来进行 deformerable conv 的调用。这里不同与官方 Deformable Conv (使用原特征进行 offset 预测), 而使用(参考特征进行 offset 预测), DCNv2Pack(num_feat, num_feat, kernel_size=3, padding=1, deformable_groups=deformable_groups) 这里输入特征channel就是特征的通道数,offset 的通道数会自动算出来。
1 | offset = torch.cat([nbr_feat_l[i - 1], ref_feat_l[i - 1]], dim=1) |
什么是 o1, o2 ? ,在 .cu 中取 data_offset_ptr , 每一个 b 会跳 2.
1 | ... |